- 04-Tutorials
-
Dask Extension¶
This notebook will give you a short introduction into the Dask Extension on JURECA. It allows you to run Jobs on the compute nodes, even if your JupyterLab is running interactively on the login node.
First you have to define on which project and partition it should be running.In [ ]:queue = "batch" # batch, gpus, develgpus, etc. project = "zam" # your project: zam, training19xx, etc.
Monte-Carlo Estimate of $\pi$¶
We want to estimate the number $\pi$ using a Monte-Carlo method exploiting that the area of a quarter circle of unit radius is $\pi/4$ and that hence the probability of any randomly chosen point in a unit square to lie in a unit circle centerd at a corner of the unit square is $\pi/4$ as well. So for N randomly chosen pairs $(x, y)$ with $x\in[0, 1)$ and $y\in[0, 1)$, we count the number $N_{circ}$ of pairs that also satisfy $(x^2 + y^2) < 1$ and estimage $\pi \approx 4 \cdot N_{circ} / N$.
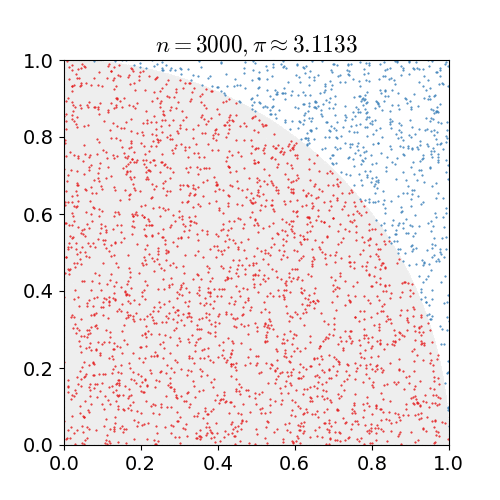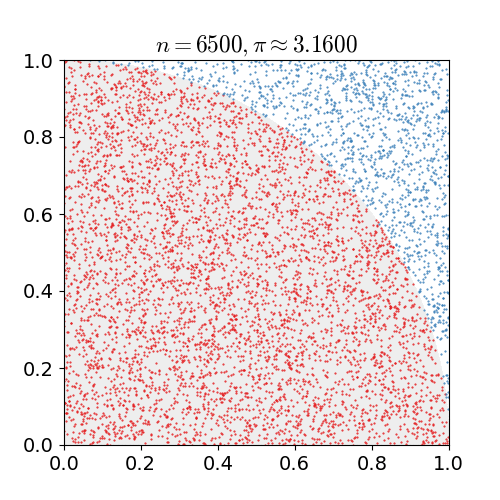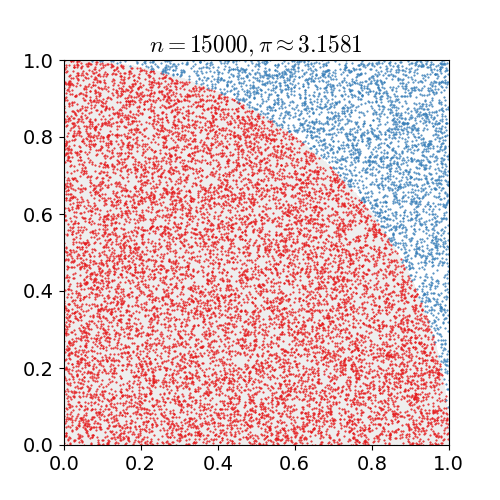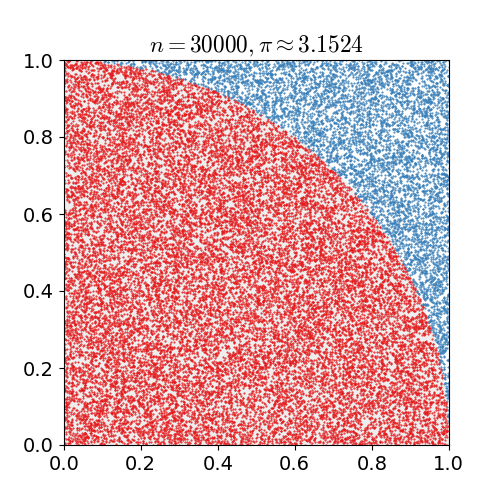
Core Lessons¶
- setting up SLURM (and other jobqueue) clusters
- Scaling clusters
- Adaptive clusters
Set up a Slurm cluster¶
We'll create a SLURM cluster and have a look at the job-script used to start workers on the HPC scheduler.
In [ ]:import dask from dask.distributed import Client from dask_jobqueue import SLURMCluster import os cluster = SLURMCluster( cores=24, processes=2, memory="100GB", shebang="#!/usr/bin/env bash", queue=queue, scheduler_options={"dashboard_address": ":56764"}, walltime="00:30:00", local_directory="/tmp", death_timeout="15s", interface="ib0", log_directory=f'{os.environ["HOME"]}/dask_jobqueue_logs/', project=project, )
In [ ]:print(cluster.job_script())
In [ ]:client = Client(cluster) client
You can visit the Dask Dashboard at the following url:¶
https://jupyter-jsc.fz-juelich.de/user/<user_name>/<lab_name>/proxy/<port>/statusYou can integrate it into your JupyterLab environment by putting the link into the Dask Extension¶

Afterwards you can press on the orange buttons to open a new tab in your JupyterLab Environment.
Scale the cluster to two nodes¶
A look at the Dashboard reveals that there are no workers in the clusetr. Let's start 4 workers (in 2 SLURM jobs).
For the distiction between workers and jobs, see the Dask jobqueue docs.
In [ ]:cluster.scale(4) # scale to 4 _workers_
The Monte Carlo Method¶
In [ ]:import dask.array as da import numpy as np def calc_pi_mc(size_in_bytes, chunksize_in_bytes=200e6): """Calculate PI using a Monte Carlo estimate.""" size = int(size_in_bytes / 8) chunksize = int(chunksize_in_bytes / 8) xy = da.random.uniform(0, 1, size=(size / 2, 2), chunks=(chunksize / 2, 2)) in_circle = (xy ** 2).sum(axis=-1) < 1 pi = 4 * in_circle.mean() return pi def print_pi_stats(size, pi, time_delta, num_workers): """Print pi, calculate offset from true value, and print some stats.""" print( f"{size / 1e9} GB\n" f"\tMC pi: {pi : 13.11f}" f"\tErr: {abs(pi - np.pi) : 10.3e}\n" f"\tWorkers: {num_workers}" f"\t\tTime: {time_delta : 7.3f}s" )
The actual calculations¶
We loop over different volumes of double-precision random numbers and estimate $\pi$ as described above.
In [ ]:from time import time, sleep
In [ ]:for size in (1e9 * n for n in (1, 10, 100)): start = time() pi = calc_pi_mc(size).compute() elaps = time() - start print_pi_stats( size, pi, time_delta=elaps, num_workers=len(cluster.scheduler.workers) )
Is it running?¶
To check if something has been started for you just use the following command in a terminal:
squeue | grep ${USER}Scaling the Cluster to twice its size¶
We increase the number of workers by 2 and the re-run the experiments.
In [ ]:new_num_workers = 2 * len(cluster.scheduler.workers) print(f"Scaling from {len(cluster.scheduler.workers)} to {new_num_workers} workers.") cluster.scale(new_num_workers) sleep(10)
In [ ]:clientRe-run same experiments with doubled cluster¶
In [ ]:for size in (1e9 * n for n in (1, 10, 100)): start = time() pi = calc_pi_mc(size).compute() elaps = time() - start print_pi_stats( size, pi, time_delta=elaps, num_workers=len(cluster.scheduler.workers) )
Automatically Scaling the Cluster¶
We want each calculation to take only a few seconds. Dask will try to add more workers to the cluster when workloads are high and remove workers when idling.
Watch how the cluster will scale down to the minimum a few seconds after being made adaptive.
In [ ]:ca = cluster.adapt(minimum=4, maximum=100) sleep(4) # Allow for scale-down
In [ ]:clientRepeat the calculation from above with larger work loads¶
(And watch the dash board!)
In [ ]:for size in (n * 1e9 for n in (1, 10, 100)): start = time() pi = calc_pi_mc(size, min(size / 1000, 500e6)).compute() elaps = time() - start print_pi_stats( size, pi, time_delta=elaps, num_workers=len(cluster.scheduler.workers) ) sleep(20) # allow for scale-down time